
中大新聞網訊(通訊員陳語謙)藥物發現和開發對制藥業和患者具有巨大的潛在利益。濕實驗技術的識別既昂貴又耗時,因此使用人工智能的方法識別潛在藥物可以顯著降低成本,大大縮短藥物研發進程。分子表示是可靠的定量活性-結構或性質-結構關系研究的基礎,但分子表示仍面臨子結構多義性、原子團間信息流不暢等幾個亟需解決的問題。
近日,我校智能工程學院陳語謙教授團隊在國際知名雜志Briefings in Bioinformatics在線發表了題為“Mol2Context-vec: learning molecular representation from context awareness for drug discovery”的研究論文。該研究提出了一種新穎的深度上下文雙向長短期記憶架構Mol2Context-vec,它可以整合不同層次的內部狀態來以動態表示分子子結構,并且獲得的分子上下文表示可以捕獲任何原子團之間的相互作用,尤其是一對拓撲上相距遙遠的原子團。
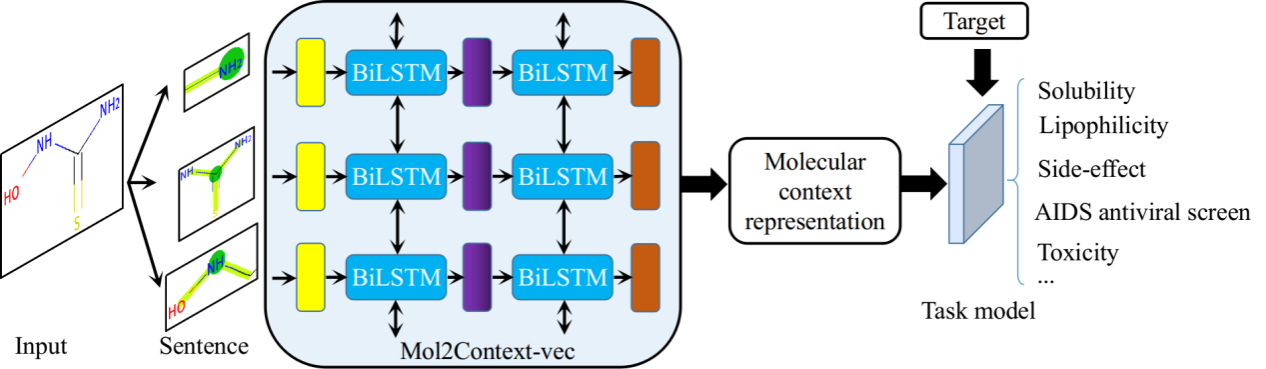
圖1. Mol2Context-vec的網絡架構和步驟概述
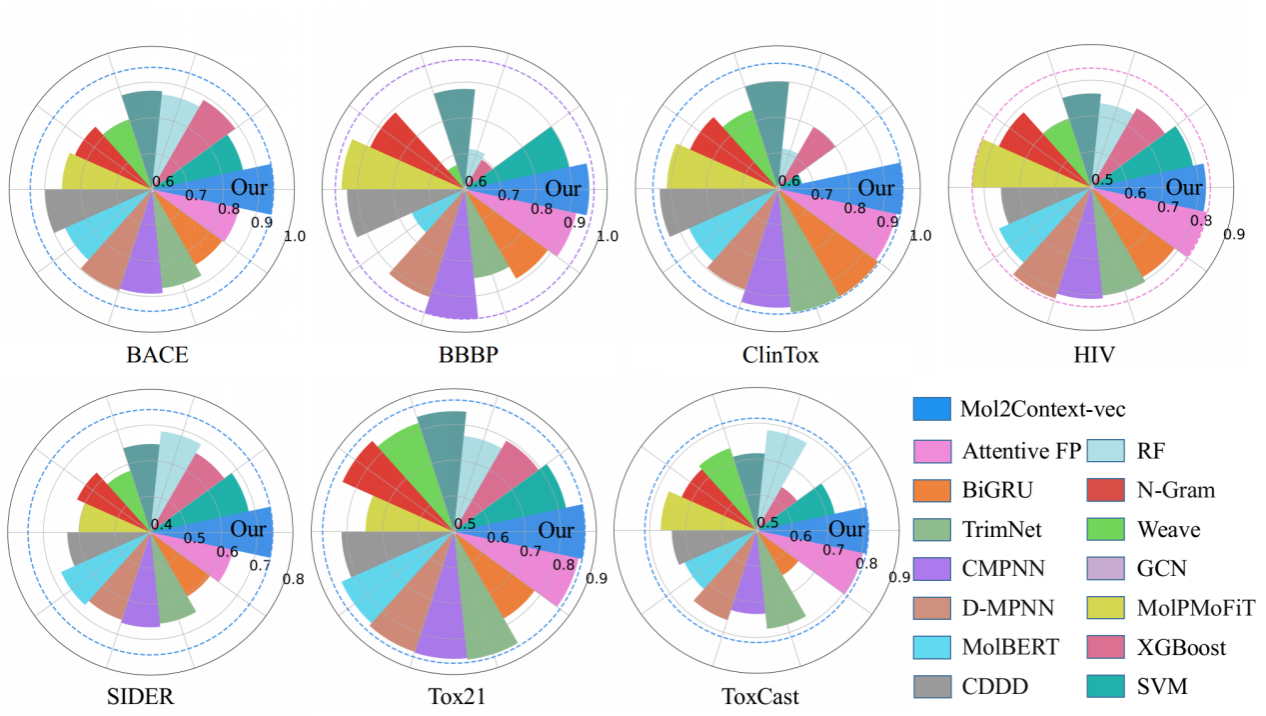
圖2. Mol2Context-vec和14種基線方法在生物活性和生理相關的基準數據集上的預測性能對比
Mol2Context-vec在大規模語料庫中使用無監督學習,結果顯示比其他模型的性能更穩定。該研究使用的分層方法使得相同子結構在不同分子中有了動態表示,對隱含捕捉分子連通性提供了新思路。Mol2Context-vec 在多個生物化學基準數據集上取得了最先進的性能,證明了該研究在促進分子表示學習方面的競爭力。該研究還提供了易于解釋的模型結果,這將增進研究人員對分子活性、毒性的潛在因素的理解。
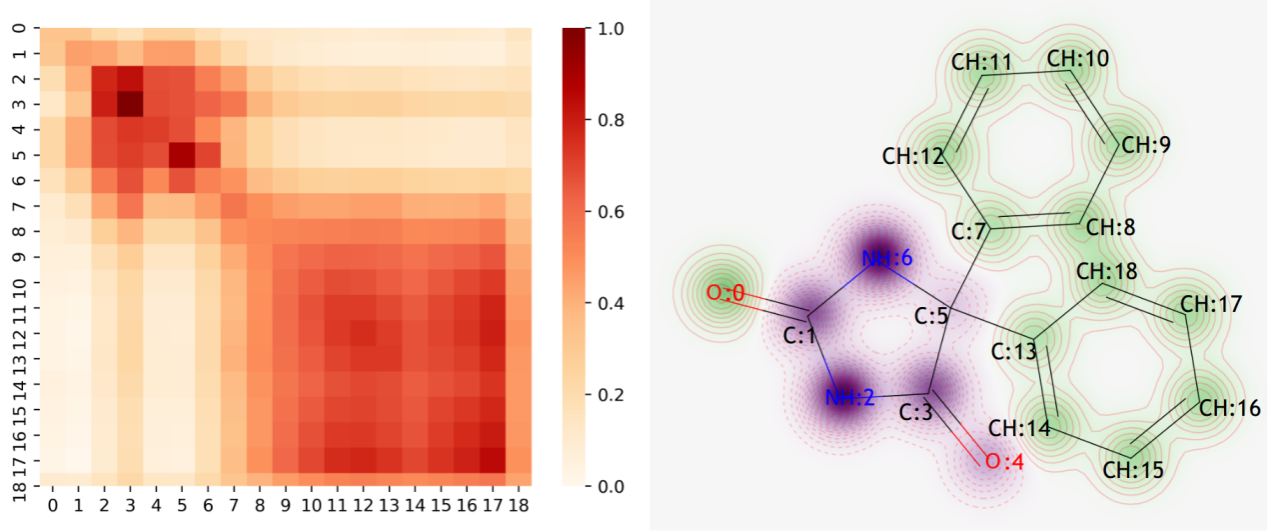
圖3. Mol2Context-vec 對苯妥英的化學直覺解釋
(a) 苯妥英原子相似度矩陣的熱圖 (b) 苯妥英分子結構中每個原子對溶解度的貢獻可視化
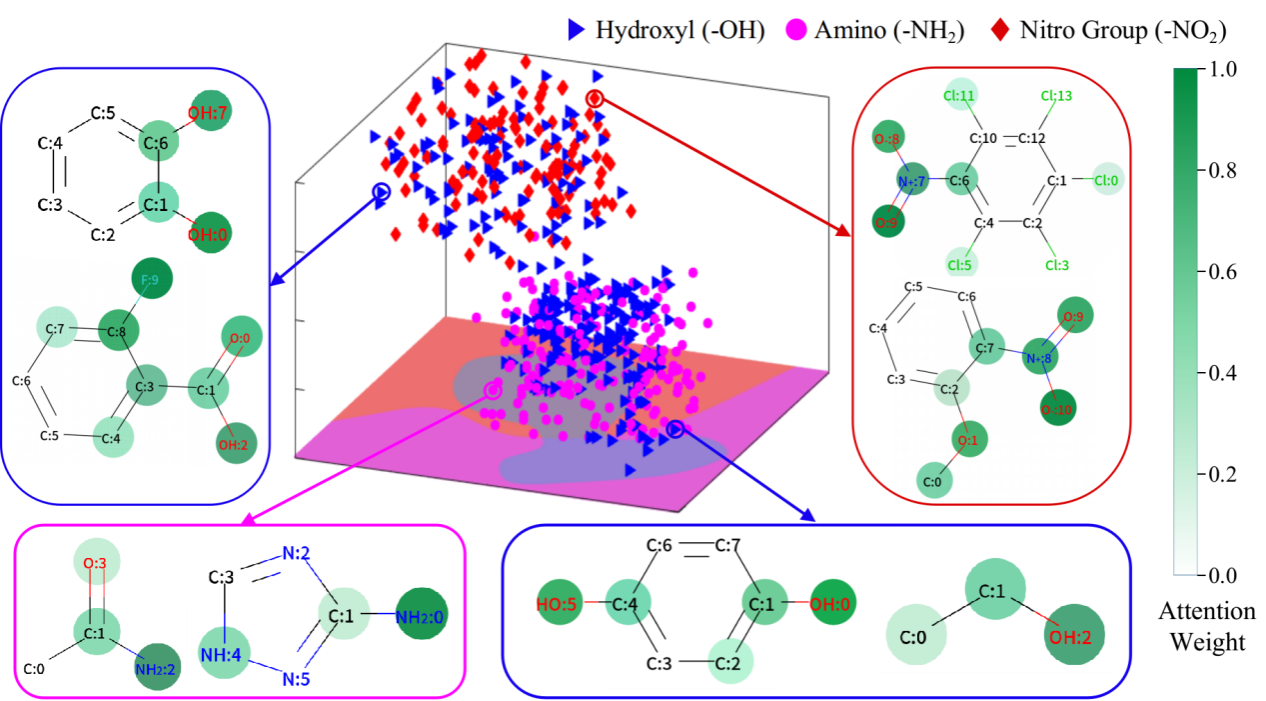
圖4. 三個子結構的高維上下文向量嵌入到3D空間中的分布可視化并顯示了其中八個分子的注意力權重
值得注意的是,Mol2Context-vec提供動態子結構表示來捕捉不同分子中相同子結構的局部效應。對于有歧義的子結構,Mol2Context-vec 生成的上下文向量正確地分離了3D空間中的不同類別。此外,多個分子的注意力權重顯示了Mol2Context-vec模型可以學習長距離關系,尤其是分子內氫鍵。提議的模型通常關注的原子團和支架非常接近人類對分子的化學理解。
陳語謙教授團隊長期致力于人工智能交叉研究。上述研究得到了國家自然科學基金面上項目(No.62176272)等項目的支持,由我校智能工程學院博士生呂秋杰在陳語謙教授指導下完成。呂秋杰為論文共同第一作者,陳語謙教授為論文通訊作者。
論文鏈接:https://academic.oup.com/bib/article/22/6/bbab317/6357185



