
近日,我校數據科學與計算機學院胡延慶副教授、馬嘯教授與孫嘉辰博士生、謝家榮博士后等在國際知名雜志《自然·通訊》(Nature Communications)上發表了題為“Revealing the predictability of intrinsic structure in complex networks”的研究論文。該研究首次發現網絡的結構可預測性與網絡結構的最短壓縮比特串長度呈線性關系,該理論可以在不依賴于任何結構預測算法的情況下,給出網絡結構可預測性的極限。
復雜網絡作為一種通用的數據表示形式,廣泛存在于生物學、推薦系統、社交媒體等各個領域。它主要用以表示復雜系統內,元素之間不能用簡單的數學來很好地描述的相互作用關系。復雜網絡結構預測技術在很多領域有廣泛的應用。例如,預測細胞內的蛋白質之間或者蛋白質與藥物的相互作用關系可以指導更精確的生物學實驗,減少實驗成本和時間。由于自然界的復雜網絡形成過程非常復雜,其結構的預測極具挑戰性。近年來學術界提出了許多機器學習方法等相關的預測算法,并致力于提高算法的性能。然而,始終缺乏對于網絡本身可預測性(最大可預測極限)的基本理解。其難點在于:網絡在形成過程中存在著十分復雜、未知的內外部因素。同時,網絡形成后的結構極其復雜,體積龐大,短程反饋回路眾多,導致一直沒有合適的數學理論來理解網絡結構可預測性的內在本質。
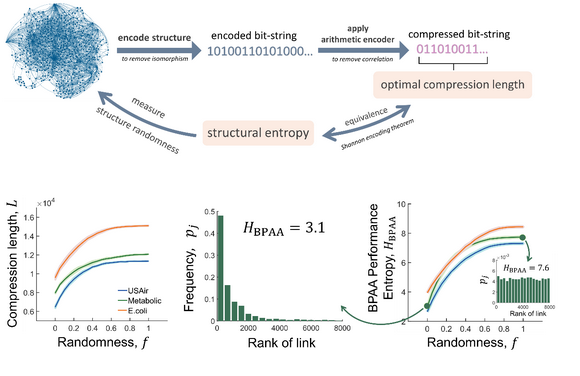
在本研究工作中,該團隊利用信息論和統計物理兩個領域中熵的相關理論,對網絡結構預測極限進行了研究。直觀地說,一個可以僅用幾個詞描述的網絡結構意味著它很簡單,其邊也很容易預測。例如二維晶格或一維鏈狀結構。相反,如果一個網絡需要很長的語言才能描述清楚,那么它應該具有非常復雜的結構,其結構很難預測。在計算機領域,任何網絡的結構都可以被編碼成二進制字符串。這啟發了團隊探尋最短二進制編碼字符串長度,也就是熵,和可預測性之間的關系。
通過研究,該團隊發現來自不同領域,很多大小不一的網絡,其結構的最短壓縮長度和可預測性之間存在一個普遍的線性關系。基于香農信源編碼定理,該團隊在隨機網絡上證明了這種線性關系。
進一步,利用這一線性關系,該團隊推導出網絡結構預測算法的性能上界,揭示出包括機器學習在內的預測算法性能尚存在多大的提升空間。因此,該性能界可用于指導未來在線商業推薦系統、蛋白質相互作用探測等場景中的算法設計。另外,該理論的一個有趣的用途是,可以實現在無需任何預測算法的情況下,通過網絡結構壓縮數據大小來估計一個網絡數據集的商業價值。
該研究受國家自然科學基金面上項目No. 61773412, U1911201等項目支持。


